B-stromy
(a,b)-tree experiment
Autor: Matěj Schrödl
1. Úvod
Tento dokument představuje praktické porovnání dvou implementací (ab)-stromu:
- (2,3) implementace
- (2,4) implementace
Jako abstraktní jednotkou času je využíván průměrný počet restrukturalizací stromu provedených během testované operace.
1.1 Vlastnosti (a,b) stromů
Použití (a,b) stromů má několik výhod:
- Díky tomu, že každý uzel může obsahovat více klíčů, dochází při vkládání a mazání k menšímu počtu vyvažovacích operací, a strom tak zůstává stabilnější.
- Pokud je hledaný klíč nalezen v uzlu, je současně snadno dostupná i celá skupina klíčů, které se v daném uzlu nacházejí. To je výhodné zejména při práci s úložišti, kde je přístup k uzlu výrazně pomalejší než čtení dat uvnitř uzlu.
- Při provádění rozsahových dotazů (např. „najdi všechny hodnoty mezi $x$ a $y$”) lze snadno načíst celé skupiny hodnot z jednotlivých uzlů, což zvyšuje efektivitu.
1.2 Relevantní axiomy (a,b) stromů
V této části jsou shrnuty základní axiomy, které definují (a,b) strom. Formulace vychází z knihy 1, přičemž jsou upraveny pro účely této práce.
[!note] Axiom 1 (O stejné hloubce listů) Všechny vnější (listové) vrcholy stromu se nacházejí ve stejné hloubce.
[!note] Axiom 2 (O počtu synů) Kořen stromu má alespoň 2 a nejvýše $b$ potomků.
Každý vnitřní vrchol (mimo kořen) má alespoň $a$ a nejvýše $b$ potomků.
1.3 Restrukturalizace
Restrukturalizace stromu znamená jakoukoliv operaci, která mění strukturu stromu za účelem zachování jeho invariantů. Každá z operací představuje změnu struktury a určitou jednotku práce ve stromu, jejich počet tedy slouží jako vhodná metrika pro hodnocení efektivity různých implementací a testovacích scénářů. V kontextu (a,b)-stromů zahrnuje restrukturalizace následující operace:
1.3.1 Split
Rozdělení přeplněného (overfull) uzlu (s více než $b$ syny) na dva uzly.
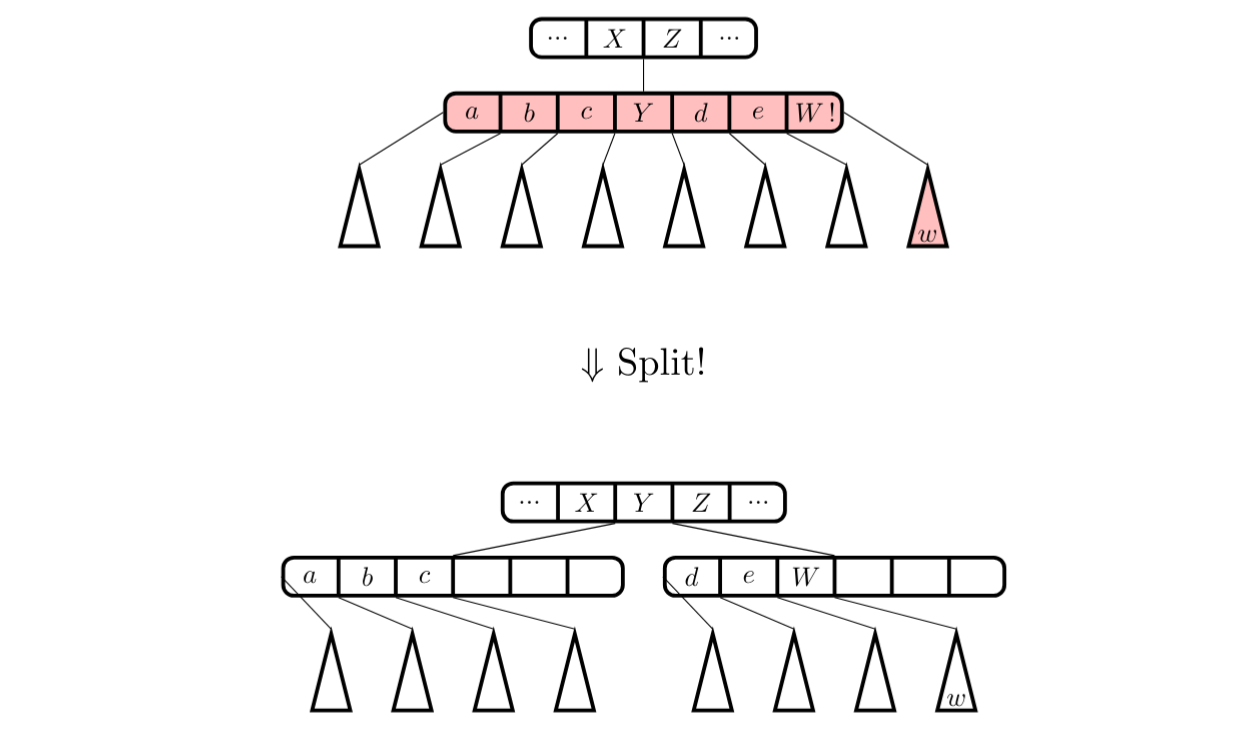 Obrázek 1: Vizualizace split operace
Obrázek 1: Vizualizace split operace
1.3.2 Merge
Sloučení dvou underfull uzlů (s méně než $a$ syny) do jednoho uzlu.
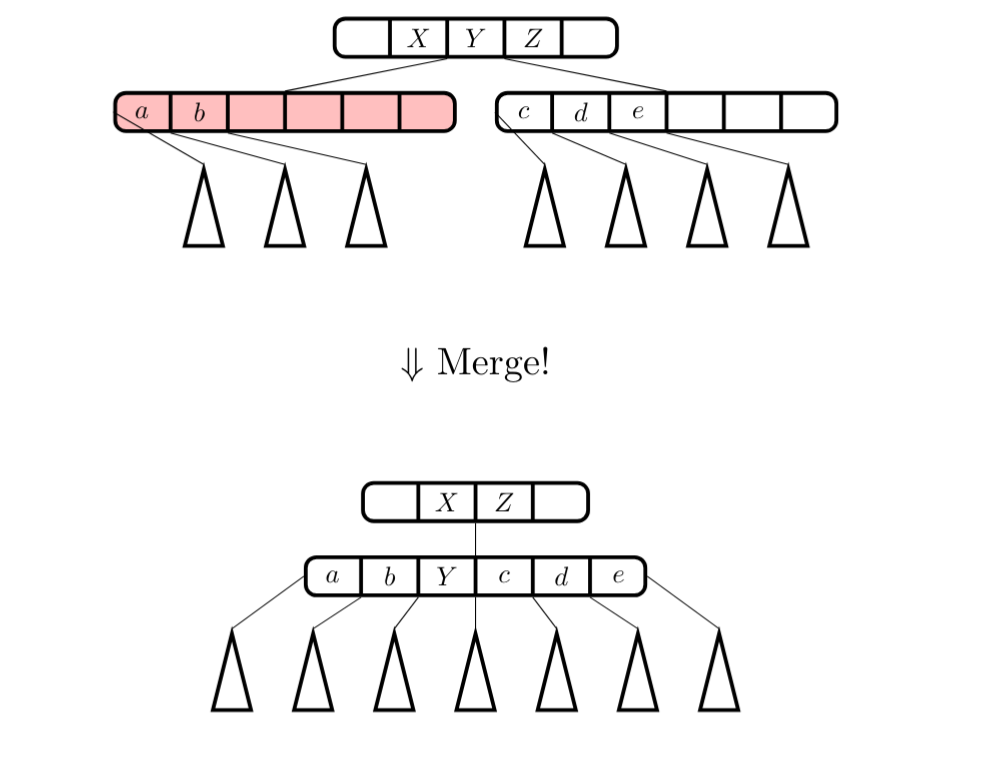 Obrázek 2: Vizualizace merge operace
Obrázek 2: Vizualizace merge operace
1.3.3 Rotace
V testované implementaci (a,b) stromu tato operace není využívána.
Rotace představuje přesun klíče mezi sousedními uzly za účelem vyvážení stromu bez změny jeho hloubky ani počtu uzlů. V některých implementacích může rotace částečně nahradit operace split nebo merge, pokud je možné strom vyvážit pouhou redistribucí klíčů mezi uzly.
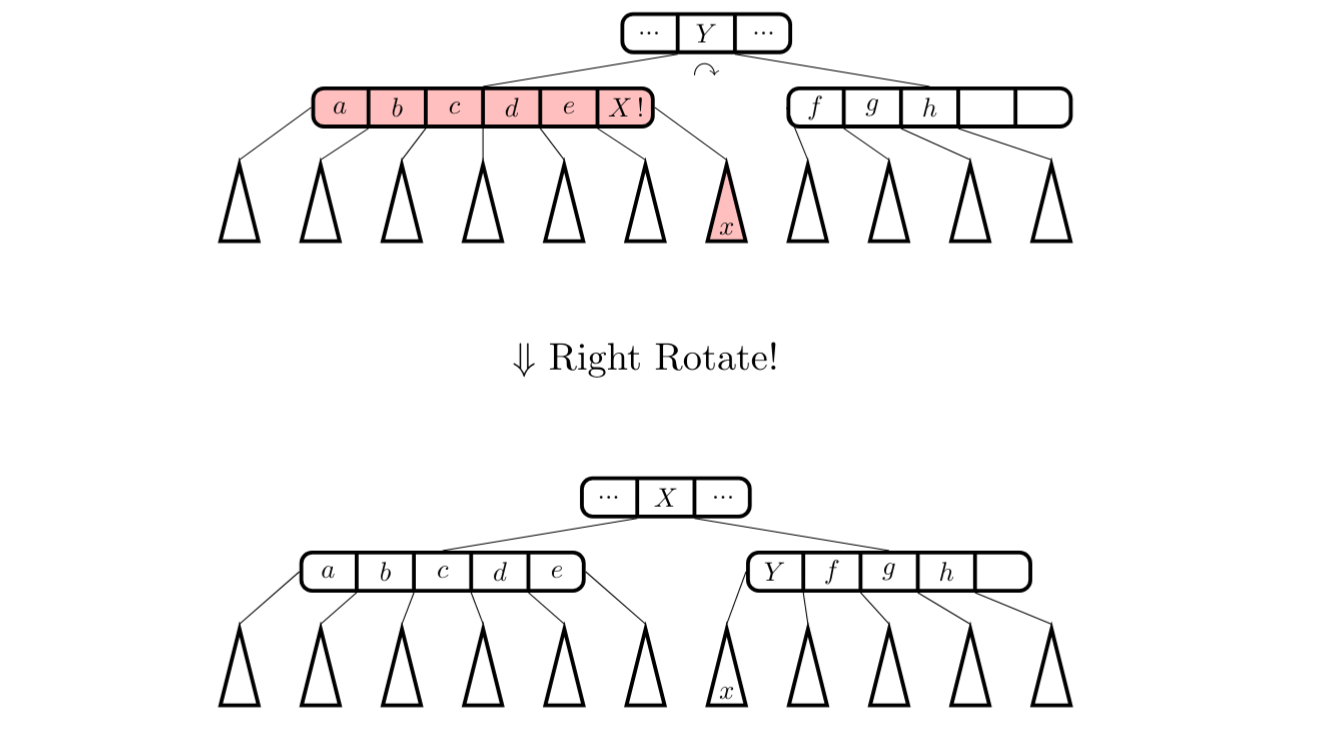 Obrázek 3: Vizualizace rotace
Obrázek 3: Vizualizace rotace
1.4 Algoritmy operací
1.4.1 Remove
Algoritmus operace insert lze stručně popsat následovně:
Pokud mazaný prvek není v listu, je nejprve nalezen jeho náhradní prvek — předchůdce nebo následovník (tyto prvky se vždy nacházejí v listech). Mazaný prvek a jeho následovník (resp. předchůdce) se mezi sebou vymění, čímž je mazání převedeno na odstranění prvku z listu.
Při mazání z listu mohou nastat dvě situace:
- List po odstranění prvku nepodteče, tj. počet jeho klíčů je $\geq a$.
- List po odstranění prvku podteče, tj. počet jeho klíčů je $< a$.
V případě (1) algoritmus končí. V případě (2) je nutné první možnost půjčit si prvek od levého či pravého bratra, pokud ani jeden z bratrů nemá dostupný prvek, je nutné provést operaci merge (případně rotaci, pokud je implementována) a restrukturalizace se může propagovat až ke kořeni. Pokud se při této propagaci dostaneme až do kořene a ten se po sloučení vyprázdní, je nahrazen svým jediným potomkem. Výsledkem je, že strom se zmenší o jednu hladinu, přičemž všechny listy zůstávají ve stejné hloubce, a axiomy stromu tak zůstávají zachovány.
Časová složitost: Každá operace merge má časovou složitost $\mathcal{O}(1)$ a může nastat nejvýše $\mathcal{O}(\log n)$-krát, tedy celková časová složitost operace remove je $\mathcal{O}(\log n)$.
1.4.2 Insert
Algoritmus operace insert lze stručně popsat následovně:
-
Hledáním vhodného místa pro nový prvek skončíme vždy v nějakém listu. Jelikož však všechny listy musí být ve stejné hloubce (Axiom 1), vkládáme prvek do rodiče listu.
- Nastanou dvě možnosti:
- (a) Prvek se do rodiče vejde — tj. počet klíčů rodiče je $\leq b-1$.
- (b) Prvek se do rodiče nevejde — po vložení by měl rodič $b$ klíčů.
-
V případě (b) je nutné provést restrukturalizaci, konkrétně operaci
Split(viz kapitola 1.3.1). Touto operací se jeden klíč přesune do rodiče. - Stejná situace se může rekurzivně opakovat i na úrovni rodiče rodiče, a to až po kořen. Pokud dojde ke
Splitukořene, vytvoří se nový kořen s jediným klíčem a dvěma syny (Axiom 2), čímž se strom prohloubí o jednu hladinu.
Časová složitost: Každá operace split má časovou složitost $\mathcal{O}(1)$ a může nastat nejvýše $\mathcal{O}(\log n)$-krát, tedy celková časová složitost operace insert je $\mathcal{O}(\log n)$.
2. Testovací metodika
Pro každou implementaci ((2-3) a (2-4)) byly provedeny tři typy testů:
- Insert - vkládání $n$ prvků v náhodné sekvenci
- Random - vkladání $n$ prvků sekvenčně a poté $n$-krát opakovat: odstranění nejmenšího prvku ve stromu a následné znovuvložení
- Min - vkládání $n$ prvků sekvenčně a poté $n$-krát opakovat: odstranění náhodného prvku ve stromu a poté vložení náhodného prkvu do stromu. Pracujeme s předpokladem, že odstranění vždy pracuje s prvkem ve stromu a vložení s prvkem, který ve stromu ještě není.
3. Insert test
Insert test slouží k otestování restrukturalizačního chování dvou implementací (a,b) stromů při postupném vkládání prvků v náhodném pořadí.
Test probíhá v několika iteracích, přičemž počet vkládaných prvků $n$ se postupně exponenciálně zvyšuje podle následujícího vztahu:
for (int e = 32; e <= 64; e++) {
int n = (int) pow(2, e / 4.0);
}
Tímto způsobem se hodnota $n$ pohybuje v rozmezí $\langle 256, 65\,536 \rangle$. Pro každou hodnotu $n$ je následně pomocí pseudonáhodného generátoru vytvořena sekvence $n$ celých čísel z intervalu $\langle 0, n \rangle$. Tato sekvence je následně vkládána do stromu pomocí operace insert. Aby bylo zajištěno spravedlivé porovnání mezi implementacemi, je pro všechny testované varianty stromů použita stejná vstupní sekvence.
3.1 Hypotéza
Pracujeme s předpokladem, že vkládáme pouze prvky, které ještě nejsou ve stromu. To vyústí v přesně $n$ operací insert pro každý strom.
3.1.1 Předpokládané výsledky
[!tip] Věta 1 (Vytvoření stromu) Sekvence $m$ operací insert na prázdném $(a,b)$-stromu vykoná $\mathcal{O}(m)$ restrukturalizací vrcholů.
Ačkoliv maximální počet restrukturalizací pro jednotlivé vložení je $\mathcal{O}(\log_b n)$, amortizovaný počet restrukturalizací na operaci insert je konstantní. Pro $m$ vložení je celkový počet restrukturalizací $\mathcal{O}(m)$, průměrná cena jedné operace tedy $\mathcal{O}(1)$.
Předpokládám, že $(2,4)$-strom bude mít nižší konstantu průměrných restrukturalizací, díky vyššímu parametru $b$, který snižuje frekvenci nutných restrukturalizací z jeho definice.
3.2 Empirická data
Následující graf využívá logaritmické škálování na ose $x$.
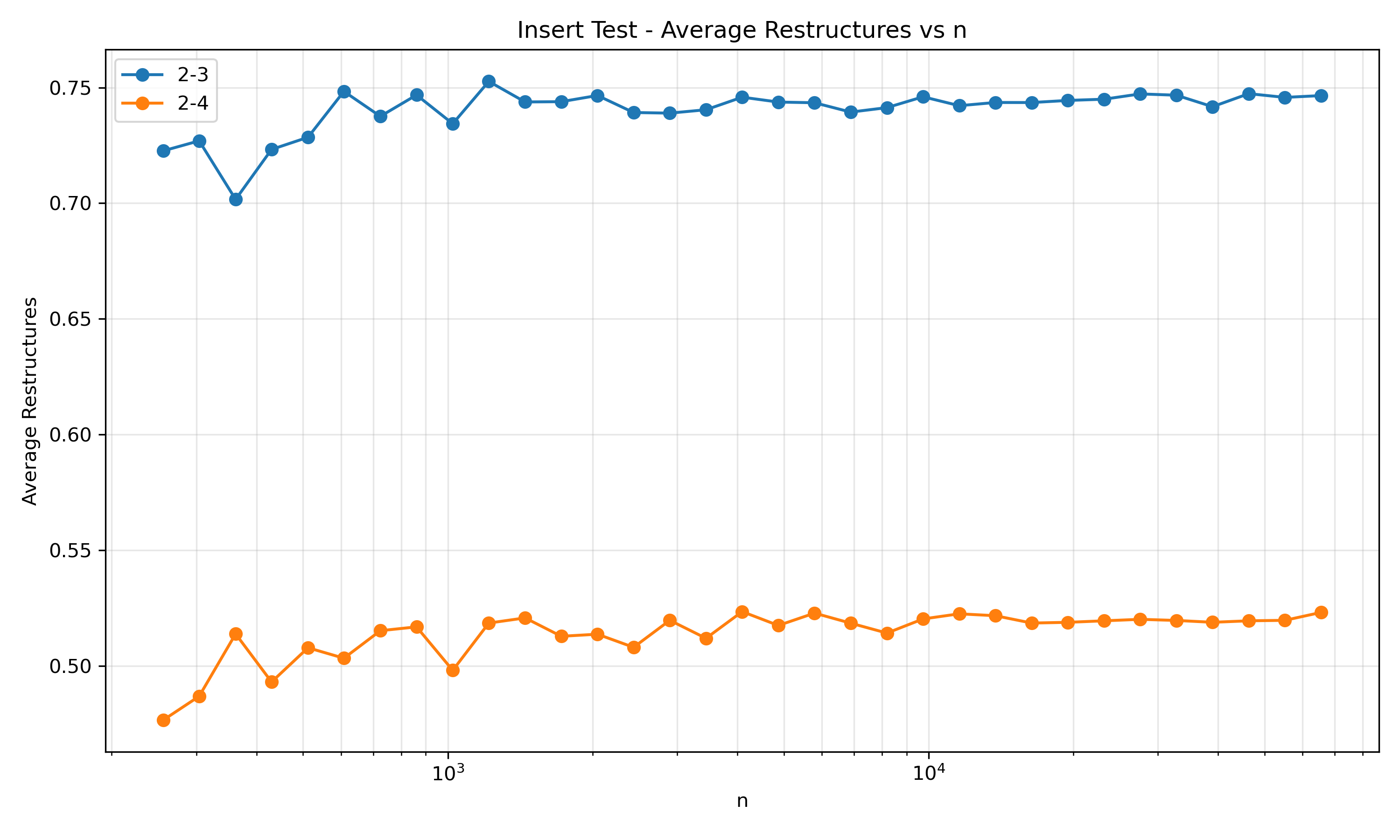 Obrázek 4: Počet restrukturalizací při operaci insert pro různé (a,b) stromy.
Obrázek 4: Počet restrukturalizací při operaci insert pro různé (a,b) stromy.
3.2.1 Závěr
Výsledky potvrzují moji hypotézu. Z experimentálně získaných dat vyplývá, že průměrný počet restrukturalizací na jeden insert je konstantní. Pro (2,3)-strom konverguje k přibližně 0,75, zatímco pro (2,4) strom je to zhruba 0,52. To potvrzuje intuici, že uzly s vyšší kapacitou (větším $b$) vyžadují méně časté rozdělování (split). Strom je proto stabilnější při vkládání náhodných prvků.
Chci ale zdůraznit, že nižší počet restrukturalizací nemusí nutně znamenat vyšší praktickou rychlost operace insert. V tomto experimentu nejsou započítány ostatní fáze vkládání, například hledání správného bloku, ve kterém má být prvek uložen. Strom typu (2,$n$) by v tomto testu vykazoval nejnižší počet restrukturalizací, avšak jeho praktická efektivita by byla nejhorší, protože každé hledání by vyžadovalo procházení lineárního množství klíčů uvnitř uzlů.
3.3 Random test
Tento experiment testuje práci stromu s náhodnými prvky a snaží se tak přiblížit jeho praktickému využití. Test probíhá následovně: do stromu je vloženo $n$ prvků pomocí operace insert. Tyto inicializační operace nejsou zahrnuty do měřených dat, neboť slouží pouze k vytvoření výchozího stavu stromu. Následně je provedeno $n$ opakování dvojice operací — odstranění náhodně vybraného prvku ze stromu a následné vložení jiného, ve stromu dosud nepřítomného prvku.
Inicializace stromu a příprava datových sad probíhá následovně:
for (int x = 0; x < 2 * n; x += 2) {
tree.insert(x);
elems.push_back(x);
}
for (int i = -1; i < 2 * n + 1; i += 2)
anti_elems.push_back(i);
Tímto způsobem je vytvořen strom obsahující sudé prvky z intervalu $\langle 0, 2n \rangle$. Proměnná elems tedy obsahuje všechny hodnoty aktuálně uložené ve stromu, zatímco anti_elems obsahuje liché hodnoty, které ve stromu zatím nejsou.
Tento test intenzivně využívá dvě stromové operace, insert a remove. Operace remove využívá druhou možnost restrukturalizace, tedy merge. Je tedy vlastně i žádoucí kromě průměrného počtu restrukturalizací porovnat i poměr mezi těmito dvěma operacemi.
3.4 Hypotéza
[!tip] Věta 2 (Věta o sekvenci operací insert a delete) Sekvence $m$ operací insert a delete na zpočátku prázdném $(a,2a)$-stromě vykoná $\mathcal{O}(m)$ restrukturalizací.
Z Věty 2 plyne konstantní amortizovaný počet restrukturalizací na operaci. Ve srovnání s Insert testem očekávám nižší počet operací split, protože konstantní velikost stromu $n$ udržovaná prokládáním operací insert a delete podporuje vyváženější strukturu.
Vzhledem ke stejnému počtu operací insert a delete předpokládám přibližně stejný počet operací split a merge s podobným růstem.
Ačkoliv Věta 2 obecně neplatí pro $(2,3)$-stromy, předpokládám u nich také konstantní amortizovaný počet restrukturalizací, protože náhodná sekvence těchto operací nenaznačuje odlišné chování. Stejně jako u předchozího Insert testu očekávám, že s rostoucím $b$ bude konstanta průměrných restrukturalizací na operaci klesat.
3.5 Empirická data
Následující graf využívá logaritmické škálování na ose $x$.
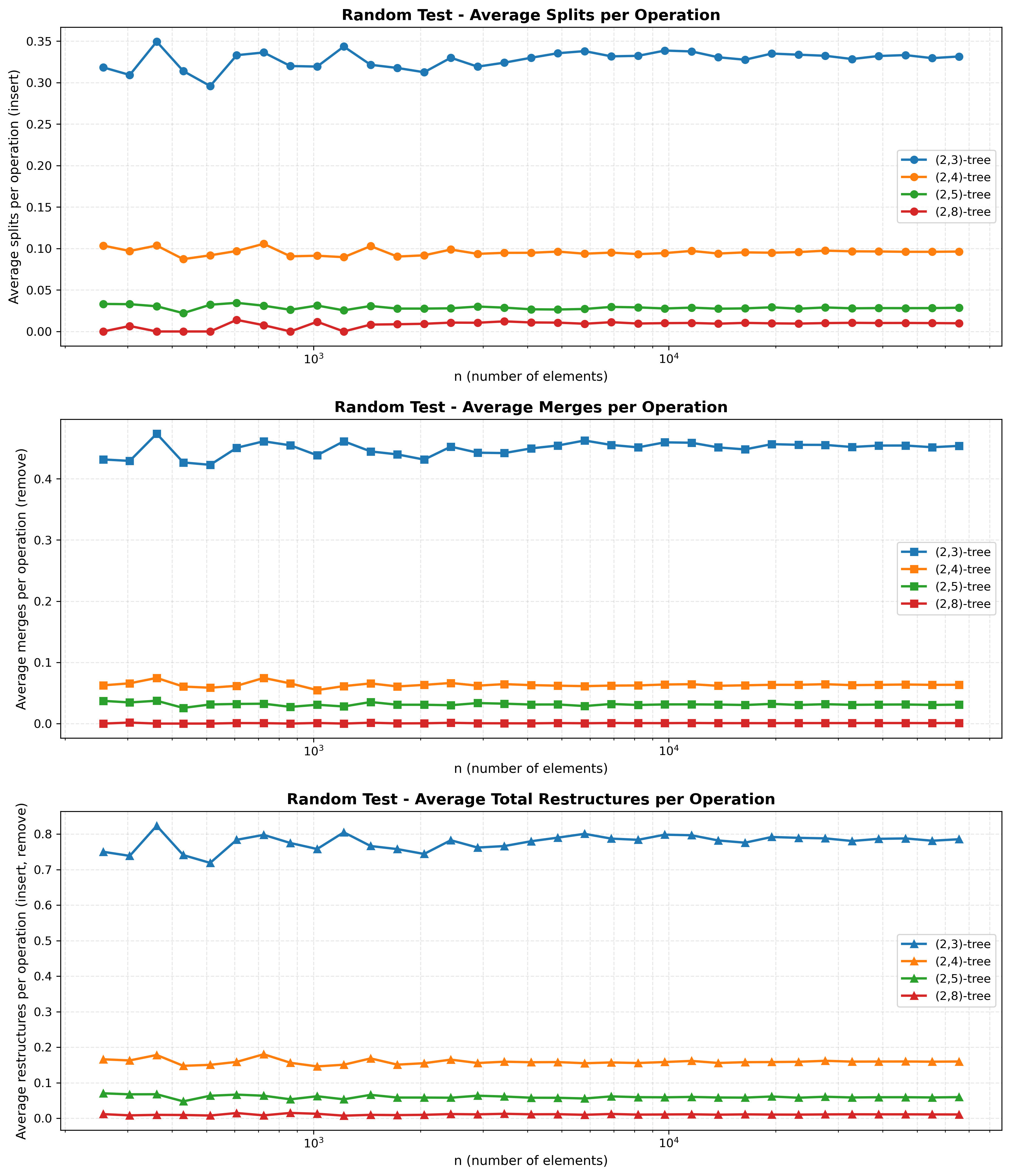 Obrázek 5: Počet restrukturalizací při random insert/delete pro různé (a,b) stromy.
Obrázek 5: Počet restrukturalizací při random insert/delete pro různé (a,b) stromy.
3.6 Závěr
Výsledky potvrzují hypotézu. Střídání operací insert a remove vede k vyváženému výskytu restrukturalizací split a merge s přibližně stejnou četností. Průměrný počet restrukturalizací na operaci zůstává konstantní nezávisle na $n$.
Stejně jako u Insert testu se s rostoucím $b$ snižuje celkový počet restrukturalizací. Stromy s vyšší kapacitou uzlů vykazují nižší frekvenci obou typů restrukturalizací vzhledem k menší pravděpodobnosti přetečení či podtečení uzlů.
Na rozdíl od Insert testu, kde strom postupně roste, Random test udržuje konstantní velikost stromu, což vede ke stabilnějšímu chování a nižšímu průměrnému počtu restrukturalizací na operaci.
4. Min test
Tento experiment testuje chování stromu při opakovaných operacích na prvku s nejmenší hodnotou, tedy v nejhlubší krajní části stromu. Do stromu je nejprve sekvenčně vloženo $n$ prvků s hodnotami $1, 2, \dots, n$. Tyto inicializační operace nejsou zahrnuty do měřených dat, protože slouží pouze k vytvoření výchozího stavu stromu.
Test demonstruje praktické rozdíly mezi $(a, 2a-1)$ a $(a, 2a)$ stromy, konkrétně mezi implementacemi $(2,3)$ a $(2,4)$.
4.1 Hypotéza
U stromů typu $(a, 2a-1)$ může opakované mazání a vkládání jednoho prvku způsobovat kmitání, kdy se střídají restrukturalizace split a merge nad stejnými uzly.
4.1.1 Kmitání v $(a, 2a-1)$-stromech
Při kombinaci operací insert a delete může v $(a, 2a-1)$-stromu nastat situace, kdy operace $\textit{insert}(x)$ vyvolá kaskádu split operací až do kořene a následující $\textit{delete}(x)$ všechny změny vrátí zpět do původního stavu. Lze tedy zkonstruovat libovolně dlouhou sekvenci operací s cenou $\Omega(\log n)$.
Princip spočívá v tom, že operace insert (způsobující split) může být bezprostředně následována operací remove (způsobující merge), což vede k neefektivnímu přeuspořádávání uzlů.
U (a, 2a–1) stromů je maximální počet klíčů v uzlu vždy sudý, konkrétně $2a-2$. Průběh operace split pak vypadá následovně:
- Uzel je plný — obsahuje $2a-2$ klíčů.
- Vložíme nový klíč, čímž dočasně vznikne $2a-1$ klíčů (lichý počet), a uzel přeteče.
- Přetečený uzel se rozdělí (split); prostřední klíč (a-tý) se posune do rodiče.
- Zbývajících $2a-2$ klíčů se rovnoměrně rozdělí mezi dva nové uzly.
- Každý nově vzniklý uzel obsahuje právě $a-1$ klíčů — tedy minimální možný počet.
Problém nastává v tom, že oba nové uzly jsou po splitu jen minimálně naplněné (viz Axiom 2). Pokud v následující operaci dojde k odstranění klíče z některého z těchto uzlů, nastane podtečení a vyvolá se merge. Tím dochází k opakovanému střídání split a merge, tedy ke zmíněnému „kmitání”.
U $(a, 2a)$ stromů k tomuto jevu nedochází, protože operace split vytváří asymetrické rozdělení — jeden z nových uzlů má $a$ klíčů, tedy o jeden klíč více než je minimum. Tento uzel má tedy “rezervu”, která umožňuje provést následující odstranění bez okamžité nutnosti merge.
V důsledku toho jsou $(a, 2a)$ stromy stabilnější při sekvenci střídajících se operací insert a remove, a proto se v praxi častěji používají než $(a, 2a–1)$ stromy.
4.1.2 Důsledek pro $(2,3)$-stromy
Předpokládám, že u $(2,3)$-stromu bude počet operací split i merge růst logaritmicky s $n$. Tento růst vykazuje zoubkovitý charakter v důsledku změn výšky stromu a logaritmické hloubky minimálního prvku.
4.2 $(a,b)$-stromy s $b = 2a$
U $(a,b)$-stromů s $b = 2a$ nastává optimální situace: opakované mazání a vkládání stejného prvku nevyvolává kmitání, a proto pravděpodobně nebude vůbec docházet k restrukturalizacím.
4.3 Empirická data
Následující graf využívá logaritmické škálování na ose $x$.
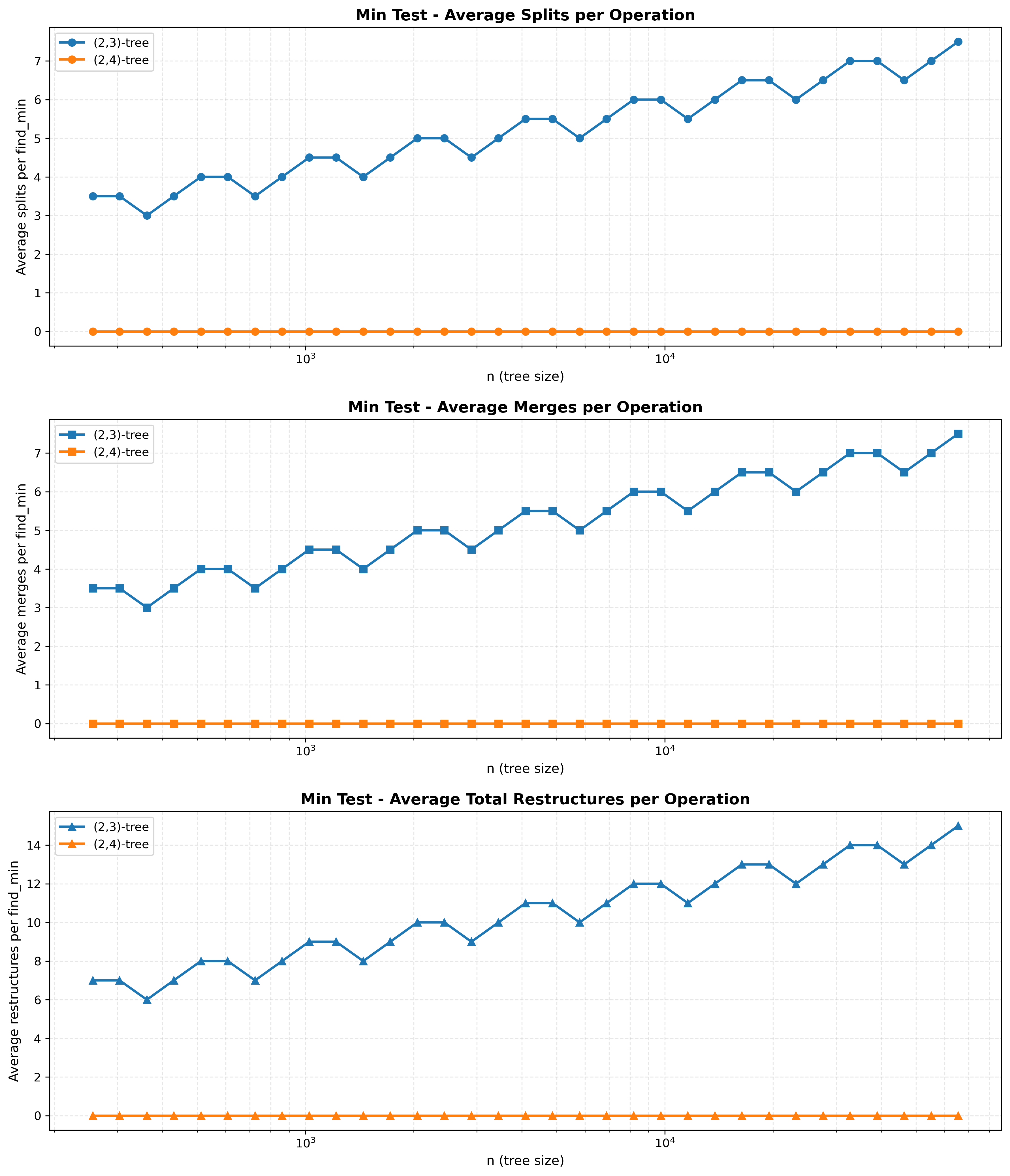 Obrázek 6: Průměrná počet restrukturalizací na operaci při vkládání a mazání nejmenšího prvku pro (2,3) a (2,4) stromy.
Obrázek 6: Průměrná počet restrukturalizací na operaci při vkládání a mazání nejmenšího prvku pro (2,3) a (2,4) stromy.
4.4 Závěr
Graf průměrného počtu restrukturalizací (součet operací split a merge) pro (2,3) strom potvrzuje hypotézu o logaritmickém růstu, který je vázán na výšku stromu $h$. Data nevykazují hladký logaritmický růst, ale zoubkovitý vzor s logaritmickým růstem.
Detailnější analýza tohoto vzoru odhalila, že “anomálie” ve vzoru, jako je náhlý pokles u $n=362$, nejsou přechody mezi výškami stromu, jak se mohlo původně zdát. Přechodové prahové hodnoty (maximální počet klíčů $n_{max}$) pro (2,3) strom s výškou $h$ jsou dány vztahem:
\[n_{max}(h) = 3^h - 1\]Z toho plynou následující prahové hodnoty pro maximální kapacitu stromu:
- Pro $h=5$ úrovní: $n_{max} = 3^5 - 1 = 242$ klíčů.
- Pro $h=6$ úrovní: $n_{max} = 3^6 - 1 = 728$ klíčů.
- Pro $h=7$ úrovní: $n_{max} = 3^7 - 1 = 2186$ klíčů.
Z této kalkulace vyplývá, že všechny naše testované stromy v rozsahu $n \in [242, 728]$ již mají shodnou výšku $h=6$.
Pokles u $n=362$ (průměrně 3.0 operace) oproti okolním bodům (prům. 3.5) tedy je pravděpodobně způsoben rozdílnou strukturou stromů o stejné výšce $h=6$. Specificky vnitřní strukturou, která vznikla při konstrukci stromu s $n=362$ prvky a která v našem specifickém testu (opakované vkládání a mazání nejmenšího prvku) dočasně vedla k efektivnějšímu pohlcení kaskádových operací. To potvrzuje i fakt, že stejný vzor vykazují jak merge tak split operace.
Reference
-
Mareš, M., & Valla, T. (2023). Průvodce labyrintem algoritmů. ↩