suffix array
Datová struktura pro práci s textem. Je to prostorově úspornější alternativa k suffix tree, přičemž nabízí stejnou funkcionalitu.
Definice
Suffixové pole je pole celých čísel, které reprezentuje lexikograficky (abecedně) seřazené indexy všech suffixů daného řetězce.
Myšlenka je jednoduchá:
- Vezmete řetězec.
- Vypíšete všechny jeho koncovky (suffixy).
- Tyto koncovky seřadíte podle abecedy.
- Místo abyste ukládali celé texty koncovek, uložíte jen číslo, kde v původním slově začínají.
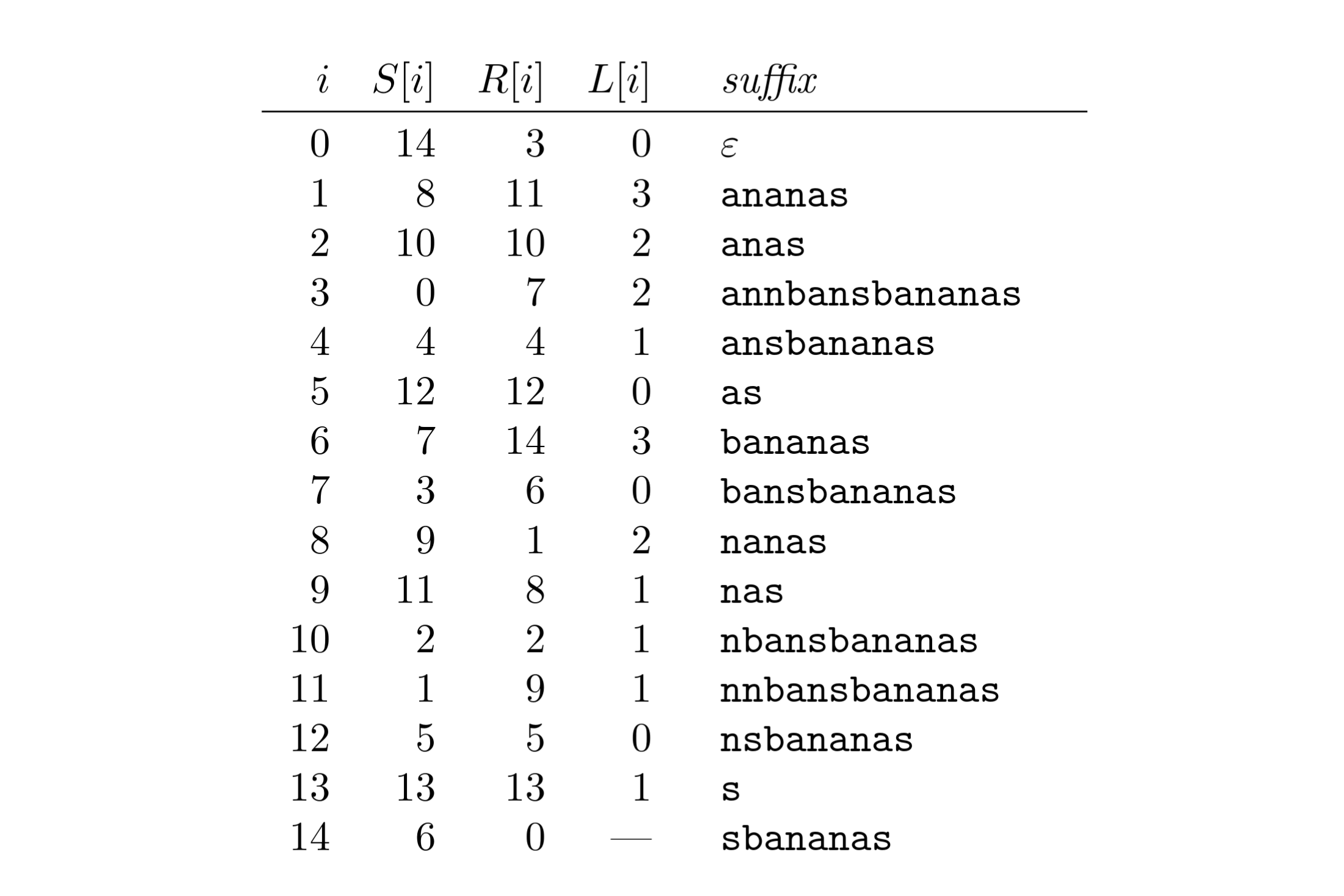
- $i$ - index
- $S[i]$ (suffixové pole) - pozice prvního písmene suffixu v původním slově (index)
- $R[i]$ (rankové pole)- kolikátý v lexikografickém pořadí je sufix $S[i \text{∶} ]$ - je to v podstatě pozice $S[x] = i$
Rankové pole může být triviálně vypočítáno ze sufixového v čase $O(n)$ (jsou mezi sebou inverzní) Důležité pole k rychlé konstrukci suffixového pole
- $L[i]$ (LCP array) - pole společných prefixů - říká kolik má $i$ společných písmen s $i+1$
Souhrn
- $S[i]:$ Říká KDO (který suffix je první, druhý…).
- $R[i]$: Říká KDE (kde v seřazeném poli je tento konkrétní suffix). Slouží k rychlému přechodu mezi indexem v textu a indexem v SA.
- $L[i]$ (LCP array): Říká JAK (jak moc jsou si sousedé podobní).
Správná mentální mapa:
- Postavíme $S$ (k tomu nutně potřebujeme $R$ při algoritmu zdvojování (#Konstrukce (algoritmus zdvojování)).
- Máme hotovo.
- Následně, pokud to úloha vyžaduje, postavíme $L$ (využijeme k tomu hotové $S$ a $R$).
[!note] Konstrukce LCP LCP array může být zkonstruováno ze suffixového pole v čase $O(n)$ (LCP array#Konstrukce (Kasaiův algoritmus))
[!important] Pozor LCP ani rank nejsou formálně součástí datové struktury suffixového pole Rankové pole se používá k optimálnímu sestavení a většina problémů, které suffixové pole řeší vyžaduje i LCP pole jako pomocnou strukturu
Samotné pole $S$ stačí na jednoduché věci (např. vyhledání výskytu vzorku v textu pomocí binárního vyhledávání ). Ale pro složitější úlohy (hledání nejdelšího společného podřetězce, komprese, histogramy k-gramů) je samotné seřazení málo – potřebujeme vědět, kde se suffixy shodují. Proto se v praxi téměř vždy po $S$ staví i $L$.
Složitost
Zde rozlišujeme složitost konstrukce (vytvoření pole) a vyhledávání.
Naivní přístup
- Konstrukce: $O(n^2 \log n)$
setřídění ($O(n \cdot \log n)$) a musíme mezi sebou porovnávat řetězce ($O(n)$)
- Vyhledání vzorku (délky $m$): $O(m \log n$)
binární vyhledávání ($O(\log n)$) a vždy musím porovnat řetězec ($O(m)$)
Optimalizovaný přístup Konstrukce: $O(n \log n)$ - algoritmus zdvojování Vyhledání vzorku (délky $m$): $O(m \log n)$
Operace
Konstrukce (algoritmus zdvojování)
Naivním způsobem (kdy postupně řadíme podle každého písmena a začínáme na $i=0$), by jsme konstruovali pole v čase $O(n \log n)$.
Můžeme, ale použít princip zdvojování, který to při správném použití zvládne za $O(n \log n)$.
Princip algoritmu: Místo abychom porovnávali celé dlouhé suffixy najednou, řadíme je postupně podle jejich prvních $k$ znaků, kde $k$ roste mocninami dvou $(1,2,4,8,…)$.
- Inicializace ($k=1$) Suffixy seřadíme jen podle prvního písmene. To zvládneme v čase $O(n \log n)$ nebo rychleji
- Krok zdvojování ($k \to 2k$)
Představme si, že už máme suffixy seřazené podle prvních $k$ znaků a známe jejich pořadí (uložené v poli $R_k$). Nyní chceme seřadit podle $2k$ znaků. Pro porovnání dvou suffixů $\alpha_i$ a $\alpha_j$ platí trik:
- dva suffixy porovnáváme jako dvojice čísel: $(R_k[i], R_k[i+k])$ a $(R_k[j], R_k[j+k])$
- první číslo říká, jak se liší první polovina $k$ znaků
- druhé číslo říká, jak se liší druhá polovina ($k$ znaků), která začíná o $k$ pozic dál
- Řazení Tuto dvojici čísel umíme porovnat v konstantním čase. Můžeme tedy použít třídící algoritmus.
Analýza složitosti:
- Celkem proběhne $O(\log n)$ průchodů (protože délka $k$ se zdvojnásobuje).
- Pokud použijeme běžné třídění (např. merge sort), trvá jeden průchod $O(n \log n)$, celkově tedy $O(n \log^2n)$.
- Vylepšení: Protože třídíme dvojice čísel od 0 do $n$, můžeme použít bucketsort. Ten seřadí dvojice v čase $O(n)$. Celková složitost pak klesne na $O(n \log n)$.
Příklad úlohy: Nejdelší společný podřetězec dvou řetězců
Existuje hodně využití suffixové pole + LCP pole (např. hledání výskytů, histogram k-gramů), ale velmi elegantní je řešení problému Longest Common Substring pro dva řetězce $\alpha$ a $\beta$.
Řešení pomocí SA a LCP
- Vytvoříme nový řetězec spojením $\alpha # \beta$, kde $#$ je unikátní oddělovač, který se v textech nevyskytuje.
- Sestrojíme suffixové pole ($S$) a LCP pole ($L$) pro tento spojený řetězec
- Protože jsou suffixy seřazené abecedně, suffixy sdílející dlouhý prefix budou v poli $S$ hned vedle sebe
- Hledáme maximální hodnotu v poli $L$, ale s podmínkou: Musíme najít takové $i$, kde suffix $S[i]$ patří do řetězce $\alpha$ a sousední suffix $S[i+1]$ patří do řetězce $\beta$ (nebo naopak)
- Největší hodnota $L[i]$ splňující tuto podmínku je délkou nejdelšího společného podřetězce.
Vztah k suffix trees
- suffix tree: Je to stromová struktura, kde každá hrana reprezentuje znaky a každá cesta od kořene k listu reprezentuje jeden suffix.
- Výhoda: Velmi intuitivní pro operace nad řetězci.
- Nevýhoda: Obrovská spotřeba paměti (mnoho ukazatelů, uzlů). Pro dlouhé texty (např. genom) je nepoužitelný.
- suffix array:
- Výhoda: Velmi kompaktní (jen pole čísel). V paměti zabere $4N$ nebo $8N$ bytů (podle velikosti integeru), což je zlomek oproti stromu.
- Ekvivalence: suffixové pole + LCP pole v sobě nesou naprosto stejnou informaci jako suffix tree. Strom se dá z pole postavit a naopak.
Další úlohy
- Histogram k-gramů (Počet výskytů podřetězců délky $k$)
- Nejdelší opakující se podřetězec