transpozice čtvercové matice
Tato implementace algoritmu se zaměřuje na co největší optimalizaci v okruhu IO operací (IO model)
Transpozice čtvercové matice
Mějme $N \times N$ matici, která je uložená jako jeden dlouhý vektor velikosti $N^2$.
Naivní přístup
Algoritmus transpozice by mohl vypadat naivně takto
for (int i = 0; i < N; i++) {
for (int j = 0; j < N; j++) {
B[j][i] = A[i][j];
}
}
Problém je takový, že přístupy k B[j][i] vždy způsobí cache miss (pokud je matice dost velká).
I/O Složitost: $O(N^2)$ - každý prvek jeden cache miss
Cache-aware přístup
Myšlenka
Myšlenka cache-aware transpozice matice spočívá v tom, že matici rozdělíme na dostatečně malé podmatice tak, aby vešly do cache.
Protože jde o cache-aware algoritmus, předpokládáme, že známe velikost cache $M$ a velikost cache bloku $B$, a podle nich můžeme zvolit velikost podmatic tak, aby se podmatice (nebo dvě) vešla do cache.
Formálněji
Rozdělíme matici na $d \times d$ podmatice. Každá podmatice na diagonále může být proházena uvnitř sebe sama. Podmatice mimo diagonálu se prohází mezi sebou.
Uvažujme, že $N$ je násobkem velikosti $B$. Pokud nastavíme $d = B$, každý řádek podmatice bude jeden blok v cache. Takže pokud máme dost cache, můžeme podmatici zprocesovat v $O(B)$ I/O operacích. Máme $\frac{N^2}{B^2}$ řádků.
I/O složitost: $O(B \cdot \frac{N^2}{B^2}) = O(\frac{N^2}{B})$ Časová složitost: $O(N^2)$ - stále musíme projít všechny prvky v matici
Nutná podmínka: Aby tento algoritmus fungoval, musí být cache schopna držet dvě podmatice naráz. Každá podmatice obsahuje $d^2 = B^2$ prvků, znamená to, že pro cache musí platit: $M \geq 2B^2$. Tomu se říká tall-cache property
Cache-oblivious přístup
Myšlenka
Nevíme žádné hodnoty o cache. Rozdělíme celou matici na 4 bloky. 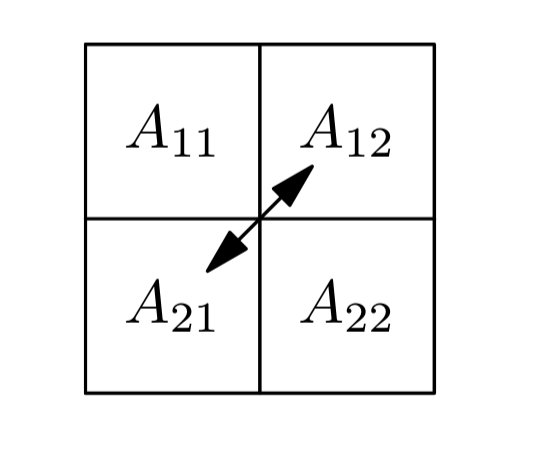 Ty rekurzivně transponujeme a swapujeme (nediagonálové). Dostaneme se tedy až na podmatice velikosti 1, kde je transpose triviální (pouze swap dvou čísel).
Ty rekurzivně transponujeme a swapujeme (nediagonálové). Dostaneme se tedy až na podmatice velikosti 1, kde je transpose triviální (pouze swap dvou čísel).
Formálně
Můžeme rozdělit matici $A$ na $2\times2$ kvadranty velikosti $N/2 \times N/2$. Kvadranty nazveme $A_{11}, A_{12}, A_{21}, A_{22}$.
Kvadranty na diagonále ($A_{11}, A_{22}$) můžeme transponovat rekurzivně. Kvadranty, které nejsou na diagonále ($A_{12}, A_{21}$) musí být transponovány, ale také se musí swapnout.
Swapování Musíme si dát pozor na to, abychom prvně netransponovali a pak swapovali.
- Na nejvyšší úrovni bychom prošli celou matici, abychom prohodili kvadranty ($N^2$ operací).
- Pak se zanořili hlouběji a v rámci menších čtverců zase procházeli všechna čísla, abychom prohodili menší pod-kvadranty.
- Ve výsledku každé číslo “přehazujeme” tolikrát, jak hluboká je rekurze (logaritmus)
Místo toho to chceme dělat in-place.
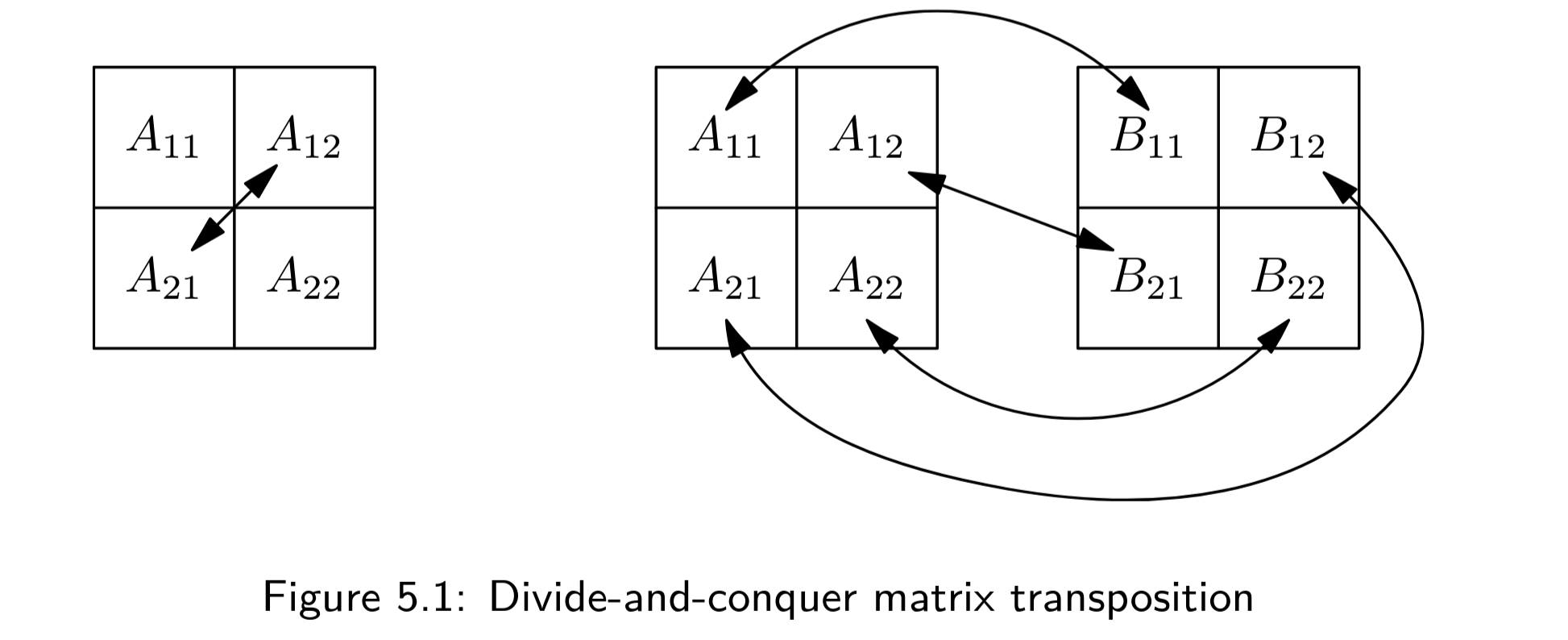 Na každé číslo v matici sáhneme právě jednou (až v momentě, kdy se dostaneme na dno rekurze, $1\times1$ matice).
Na každé číslo v matici sáhneme právě jednou (až v momentě, kdy se dostaneme na dno rekurze, $1\times1$ matice).
implementace: matrix_transpose()
Odvození složitosti
transpose_and_swap()($TS$) tedy rekurzí na 4 podproblémy, které jsou zase $TS$transpose()($T$) rekurzí na 3 podproblémy - 2 $T$ a 1 $TS$.
Na hladině $i$ můžeme tedy mít maximálně $4^i$ podproblémů velikosti $N/2^i$. Tedy velikost stromu rekurzí bude mít hloubku $\log N$ a až $4^{\log N} = N^2$ listů.
V každém listu uděláme max $O(1)$ práce (pokud je to $TS$ list) tedy $O(1) \cdot N^2$ listů je časová složitost $O(N^2)$.
Pro I/O složitost využijeme stejný princip jako v cache-aware algoritmu. Najdeme nejmenší hladinu $i$, kde platí $d = N/2^i \leq B$ (jeden řádek do jednoho bloku). Protože víme, že pro $i-1$ neplatí $2d= N/2^{i-1} \leq B$ (jinak by hladina $i$ nebyla nejmenší). Z toho plyne, že $B/2 < d \leq B$.
Teď jak z téhle informace dostat I/O složitost? Můžeme využít následující strategii cachování: Nad hladinou $i$ necachujeme nic (ničeho se nedotýkáme, což je v pořádku). Když dorazíme s do hladiny $i$, načteme celý podproblém do cache a rovnou vypočteme celý podstrom tohoto podproblému. Nikdy už ho nebudeme muset načíst znovu. To uděláme ve všech prvkách hladiny $i$. To je vlastně úplně ekvivalentní jako náš cache-aware přístup a tedy představuje složitost $O(\frac{N^2}{B+1})$
I/O složitost: $O(\frac{N^2}{B+1})$ časová složitost: $O(N^2)$