range tree
Range tree je statická binární stromová datová struktura (podobně jako k-d trees), která je navíc víceúrovňová a je určená pro efektivní zpracování rozsahových dotazů
Motivace
Mějme množinu bodů \(P=\{p_1,p_2,…,p_n\},p_i \in \mathbb{R^d}\) a chceme efektivně odpovídat na rozsahové dotazy (range queries) typu:
Najdi všechny body $p \in P$, které leží v osově zarovnaném hyper-obdélníku (pokud by byl obdélník natočený, nelze dotaz rozložit na nezávislé intervaly po osách) \(Q = [a_1, b_1] \times [a_2, b_2] \times \dots \times [a_d, b_d]\) —
Definice (pro 2D případ)
Range tree ve 2D je vyvážený binární vyhledávací strom podle jedné souřadnice (typicky $x$), kde každý vrchol obsahuje asociovanou strukturu pro druhou souřadnici ($y$).
Formálně
- Primární strom $T_x$:
- je vyvážený BST nad hodnotami $x$-ových souřadnic bodů
- každý uzel $v$ reprezentuje podmnožinu bodů $P(v)$
- Asociovaná struktura $T_y(v)$:
-
vyhledávací struktura (typicky setříděné pole nebo BST)
Konstrukce (2D)
- Body seřadíme podle souřadnice $x$
- Rekurzivně postavíme vyvážený binární strom:
- levý podstrom: body s menším $x$
- pravý podstrom: body s větším $x$
- Pro každý uzel:
- vytvoříme asociovaný seznam bodů
- tento seznam je setříděn podle souřadnice $y$
-
Konstrukce trvá: \(O(n \log n)\)
- Stavba Y-stromů na jedné hladině X-stromu trvá $O(n)$.
- Protože X-strom je dokonale vyvážený, má hloubku $O(\log n)$.
Operace
find_in_range(Q)
Dotaz: \(Q = [x_1, x_2] \times [y_1, y_2]\)
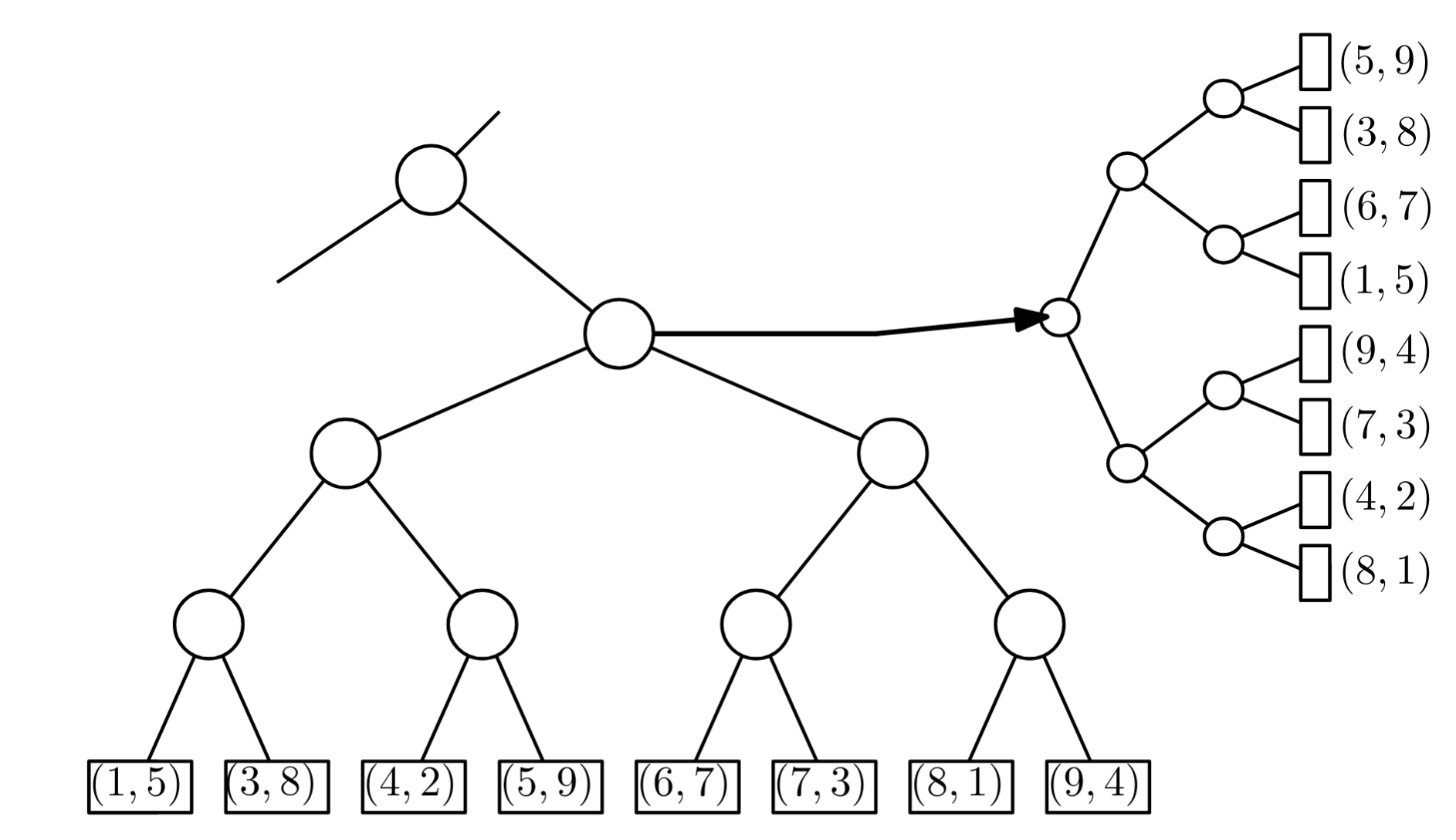
1. Práce v primárním X-stromě (hledání kandidátů)
Cílem této fáze je najít množinu podstromů, které obsahují přesně ty body, jejichž x-ová souřadnice je v intervalu $[x_1,x_2]$. O $y$ se zatím nestaráme.
- Nalezení rozdělovacího vrcholu ($v_\text{split}$):
- Začneme v kořeni a hledáme cestu k $x_1$ i $x_2$ zároveň.
- Dokud jsou oba $x_1$ i $x_2$ menší než aktuální uzel, jdeme doleva.
- Dokud jsou oba větší, jdeme doprava.
- V momentě, kdy se cesty rozejdou ($x_1≤\text{value}≤x_2$), jsme našli $v_\text{split}$.
- Cesta k levému okraji ($x_1$):
- Od $v_\text{split}$ jdeme směrem k hodnotě $x_1$.
- Kdykoliv se pohneme doleva (jdeme k $x_1$), znamená to, že pravý syn aktuálního uzlu má hodnoty větší než $x_1$ (ale stále menší než $v_\text{split}$, tedy menší než $x_2$).
- Akce: Tento pravý podstrom celý vybereme jako “kanonický uzel”. Všechny body v něm mají $x$ v pořádku.
- Kdykoliv jdeme doprava, levý syn je moc malý ($<x_1$), takže ho ignorujeme.
- Cesta k pravému okraji ($x_2$):
- Od $v_\text{split}$ jdeme směrem k hodnotě $x_2$.
- Kdykoliv se pohneme doprava, znamená to, že levý syn je menší než $x_2$ (a větší než $v_\text{split}≥x_1$).
- Akce: Tento levý podstrom celý vybereme.
- Kdykoliv jdeme doleva, pravý syn je moc velký ($>x_2$), ignorujeme ho.
Výsledek fáze 1: Našli jsme $O(\log n)$ podstromů (kanonických uzlů). Pro všechny body v těchto podstromech platí: “Máme jistotu, že vaše x je správně.”
2. Přepnutí do sekundárních Y-stromů
Nesestupujeme do vybraných (v předchozím kroku) podstromů v X-stromě (to by bylo pomalé).
Místo toho pro každý vybraný kanonický uzel v:
- Vezmeme jeho asociovaný Y-strom ($T_y(v)$).
- Tento strom obsahuje identickou sadu bodů jako X-podstrom pod $v$, ale jsou seřazené podle y.
- Nad tímto Y-stromem spustíme 1D Range Query pro interval $[y_1,y_2]$.
Shrnutí složitosti dotazu
\(O(\log^2 n+k)\)
- Výběr v X-stromě: Navštívíme $O(\log n)$ uzlů, abychom našli ty kanonické podstromy.
- Počet Y-stromů: Našli jsme jich maximálně $O(\log n)$.
- Práce v jednom Y-stromě: 1D hledání trvá $O(\log n)$.
- Celkem:
$O(\log n)×O(\log n)=O(\log^2 n)$
-
(Plus $O(k)$ na vypsání k nalezených bodů).
-
Časová složitost (2D)
- Výška primárního stromu: $O(\log n)$
- Počet relevantních uzlů: $O(\log n)$
- Vyhledání v asociované struktuře: $O(\log n)$
Celková složitost dotazu: \(O(\log^2 n + k)\) kde $k$ je počet nalezených bodů
[!note] Proč? Nejprve v primárním stromě hledáme rozsah souřadnic $[x_1,x_2]$. To znamená $O(\log n)$ vrcholů. Víme, že všechny body v těchto podstromech splňují podmínku pro $x$. Musíme ale odfiltrovat ty, které nesplňují podmínku pro $y$. Prohledání jednoho $y$ je $O(\log n)$
Paměťová složitost (2D)
Každý bod je v $\log n$ stromech (na své cestě v primárním stromě): \(O(n \log n)\)
Zobecněná do $d$ rozměrů
Range tree lze rekurzivně zobecnit:
- primární strom podle 1. souřadnice
- v každém uzlu range tree pro $(d-1)$-rozměrný problém
Složitost
- Paměť: \(O(n \log^{d-1}n)\)
- Dotaz:
\(O(\log^d n + k)\)
-
$k$ je složitost vypsání nalezených bodů
-
Optimalizace (fractional cascading)
Použitím fractional cascading lze snížit dotazovou složitost:
-
2D: \(O(\log n + k)\)
-
Obecně: \(O(\log^{d-1} n + k)\)
Myšlenka je že poslední dimenzi nahradíme místo BST nebo setříděného pole. Fractional cascading je technika, která umožňuje sdílet výsledek binárního vyhledávání mezi více setříděnými strukturami.
V range tree tím eliminujeme nutnost provádět binární vyhledání v každé asociované struktuře zvlášť.
Po jednom binárním vyhledání:
- další vyhledávání probíhají v $O(1)$ čase
Tím se tedy zbavíme logaritmu z poslední struktury: $O(\log^d n)$ na $O(\log^{d-1} n)$
Dynamizace
Problémem těchto stromů je, že rotace (typický princip balancování) by vynutily kompletní přestavbu sekundárních stromu ($y$-stromů), což je příliš drahé.
Využívají se proto líné váhově vyvážené stromy
insert
Princip vkládání Při vložení nového bodu $(x,y)$ musíme aktualizovat strukturu na dvou úrovních:
- $x$-strom (primární): pokud souřadnice ve stromě není, vložíme nový uzel
- $y$-stromy (sekundární): bod musíme vložit do všech $y$-stromů, které přísluší uzlům na cestě k listu v $x$-stromě. Těchto $y$-stromů je $O(\log n)$
Řešení vyvažování Abychom udrželi strom vyvážený, používáme strategii váhového vyvažování (pokud se podstrom stane příliš “těžkým” vůči svému sourozenci, celý ho zboříme a znovu postavíme dokonale vyvážený).
Vyvažování $y$-stromů: Vložení prvku může vyvolat potřebu přestavět některý $y$-strom. Přestavba jednoho $y$-stromu je levná (lineární vzhledem k jeho velikosti). Amortizovaná cena za vyvažování všech dotčených y-stromů je $O(\log^2 n)$.
[!note] Vysvětlení Mám jeden obyčejný BB(alpha) strom (y-strom) a vkládáš do něj prvek.
- Pokud se tento strom stane nevyváženým, musíme ho přestavět.
- Jak jsme si odvodili u BB(alpha) tree (weight balanced tree) stromů: Ačkoliv přestavba stojí $O(n)$, děje se tak vzácně, že amortizovaná cena vložení do jednoho BB(alpha) stromu je $O(\log n)$.
Při vložení bodu (x,y) procházíme x-strom od kořene k listu.
- Cesta má délku $O(\log n)$.
- V každém uzlu této cesty musíme aktualizovat jeho y-strom.
To znamená, že musíme provést operaci
insertdo $\log n$ nezávislých y-stromů.
Vyvažování $x$-stromu: Pokud se naruší rovnováha v primárním x-stromě, musíme přestavět celý podstrom x-stromu o velikosti $m$. To je drahé, protože to zahrnuje i konstrukci všech vnitřních $y$-stromů. Cena : \(O(m \log m)\)
- $\log m$ $y$-stromů s lineárním časem konstrukce ($m$)
Díky vlastnostem váhově vyvážených stromů se to však děje zřídka (po $\Omega(n)$ vloženích). Amortizovaná cena tohoto kroku je také $O(\log^2 n)$.
[!note] Intuice
- přestavba jedné hladiny znamená $n$ práce (všechny prvky musíme dát do nějakého $y$ stromu) a hladin je $\log n$
[!note] Podmínka Aby platilo, že práce na hladině je lineární ($O(m)$), musíme mít splněnou jednu podmínku:
- body už musí být seřazené podle y.
Výsledná složitost
Celková amortizovaná časová složitost operace insert(x) v dynamickém 2D intervalovém stromě je $O(\log^2 n)$.